![]()
Back in June, I had the opportunity to speak at the
SANS DFIR Summit. One of the great things about this conference was the ability to meet and socialize with all the attendees and presenters. While I was there, I had a chance to catch up with Sarah Edwards who teaches the Mac 518 class for SANS.
I'm always looking for new projects to work on, and she suggested a script to parse Safari Internet History. So the 4th of July long weekend rolled around and I had some spare time to devote to a project. In between the fireworks and a couple of Netflix shows (OK, maybe 10 shows), I put together a python script that parses out several plist files related to Safari Internet History: History.plist, Bookmarks.plist, TopSites.plist and Downloads.plist.
Since the iPhone also uses Safari, I decided to expand the script to parse some iPhone Safari artifacts: History.plist, Bookmarks.db and RecentSearches.plist. I imagine the iPad also contains Safari Internet History, but I did not have one at my disposal to test. If you want to send one to me for testing, I would be happy to take it off your hands :-).
In this post I'll run through each of the artifacts I located and explain how to use the script to parse out the files.
Plist Files: A love/hate relationship
First, a little background on plist files. Plist files are awesome because they can contain all sorts of information such as Internet History, Recent Docs, Network IDs etc. There are free tools for both Windows and OS X that will allow you view the data stored in the plist file. For Windows, you can use
plist Editor. If you have a Mac, a free plist editor is included in Apple's XCode Developer Tools which can be downloaded through the App Store.
However, plist files also stink because while the plist format is standardized, it's entirely up to the programmer to store
whateverthey want, in
whatever format they want.
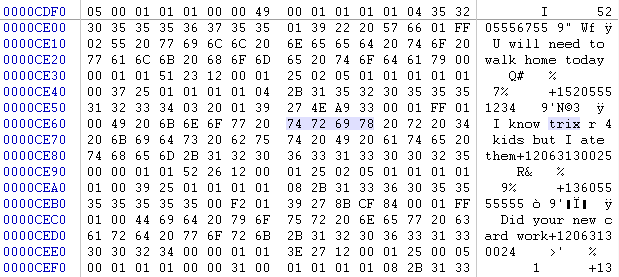
A (frustrating) example of this is date information. In the Safari History.plist file the date is defined as a "String", and is stored in Mac Absolute time. Mac Absolute time is the number of seconds since
June January 1, 2001. Below is an example of this from a Safari History.plist file viewed in the XCode plist editor:
![]() |
| History.plist file in XCode plist editor |
In the Safari Bookmarks.plist file, the date is stored in a field defined as "Date".The date is stored in a more standard format:
![]() |
| Bookmarks.plist file in XCode plist editor |
This means that each plist file needs to reviewed manually to determine what format the data is in, and how it's stored before it can be parsed.
So, moving on to the artifacts...
Where's the beef?
On a Mac OS X, the Safari Internet History is located under the folder /Users/%USERNAME%/Library/Safari. As I mentioned before, I located four plist files in this folder containing Internet History: History.plist, Bookmarks.plist, TopSites.plist and Downloads.plist. I've written the script to read either an individual file, or the entire folder at once.
(If you're wondering about the Safari cookie files, I already wrote a separate tool support these, which can be found on my
downloads page.)
History.plistThis file contains the the last visited date, URL, page title and visit count. To run the parser over this file and get a tsv file use the following syntax:
safari_parser.py --history -f history.plist -o history-results.tsv
TopSites.plistThe Top Site feature of Safari identifies 12 Top Sites based upon how often and how recent the sites were visited. There are several ways to view the tops sites in Safari, such as starting a new tab or selecting it from the Menu>View>Top Sites. Small thumbnails of each Top Site are displayed. The user has the option to Pin or Delete a site from the Top Sites. Pinning a site keeps it in the Top Sites List, while deleting it removes it. The list can be increased to hold up to 24 sites.
The thumbnails for the webpage previews for Safari can be found under /Users/%Username%/Library/Caches/com.apple.Safari. Below is how the TopSites appear to a user ( this may vary depending on the browser version):
The TopSite.plist file contains the Page Title and URL. It also stores values to indicate if it's a Pinned or Built in Site. Built in Sites are pre-populated sites such as iCloud or the Apple Website.
TopSites that have been deleted are tracked in the TopSites.plist as "BannedURLStrings".
To parse the TopSites.plist file use the following syntax:
safari_parser.py --topsites -f TopSites.plist -o topsite-results.tsv
Downloads.plistDownloads are stored in the Downloads.plist file. When a file is downloaded, an entry is made containing the following: 1)Download URL; 2)File name including the path where it was downloaded to; 3)Size of the file; 4)Number of bytes downloaded so far. The user may clear this list at anytime by selecting "Clear" from the Downloads dialog box:
To parse the Downloads.plist file use the following syntax:
safari_parser.py --downloads -f Downloads.plist -o download-results.tsv
Bookmarks.plistSafari tracks three different types of bookmarks in the Bookmarks.plist file: Favorites, Bookmarks and the Reading List.
FavoritesThe Bookmarks Bar (aka Favorites) is located at the top of the browser:
The Favorites are also displayed on the side bar:
Bookmark MenuA folder titled "Bookmark Menu" is created by default when a user creates bookmarks. It contains a hierarchical structure of bookmarks and folders - these are shown in the red box below:
The user may add folders, as demonstrated with the "test bookmarks" folder below:
Reading ListThe Reading List is another type of bookmark. According to Safari documentation, "Reading List helps you save webpages and links for you to read later, even when you are not connected to the internet". These items show up when the user selects the Reading List icon:
Safari downloads and stores information such as cached pages related to the Reading List under /Users/%USERNAME%/Library/Safari/ReadingListArchives. I didn't spend too much time researching this as my parser is focused on the bookmarks.plist file, but keep it in mind as it may turn up some interesting stuff.
All three types of bookmarks (Favorites, Bookmarks and Reading Lists) are stored in the Bookmarks.plist file.
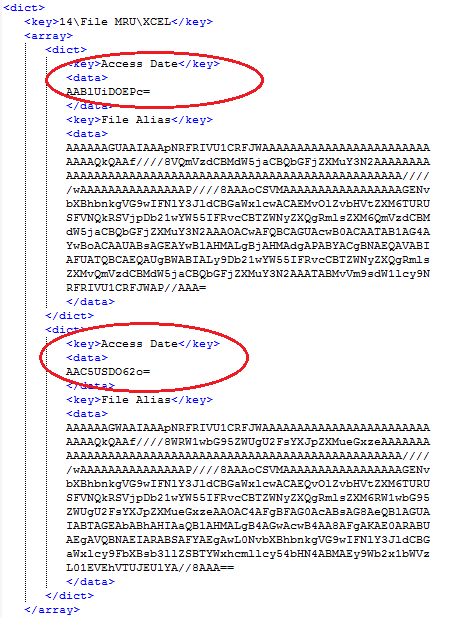
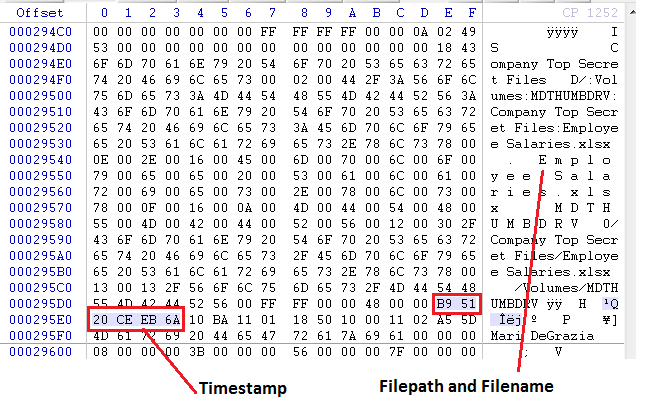
The Bookmarks.plist file tracks the Page Title and URL for the Favorites and the Bookmarks, however, the Reading List entries contain a little bit more information. The Reading Lists also contains a date added, date last fetched, fetch result, and preview text. There are also a couple of boolean entries, Added Locally and Archived on Disk.
Out of all the plist files mentioned so far, I think this one looks the most confusing in the plist editor programs. The parent/child relationships of the folders and sub folders can get pretty messy:
To parse the Bookmarks.plist file, use the following syntax:
safari_parser.py --bookmarks -f Bookmarks.plist -o bookmark-results.tsv
The Safari Parser will output this into a spreadsheet with the folder structure rebuilt, which is hopefully more intuitive then viewing in the plist editor:
All Four One and One for AllInstead of parsing each file individually, all four files can be parsed by pointing Safari Parser to a folder containing all four files. This means you can export out the /Users/%Username%/Library/Safari folder and point the script at it. You could also mount the image and point it to the mounted folder. To parse the folder, use the following syntax:
safari_parser.py -d /Users/maridegrazia/Library/Safari -o /Cases/InternetHistory/Reports
This will create four tsv files with results from each of the above Internet History Files.
iPhone Internet History
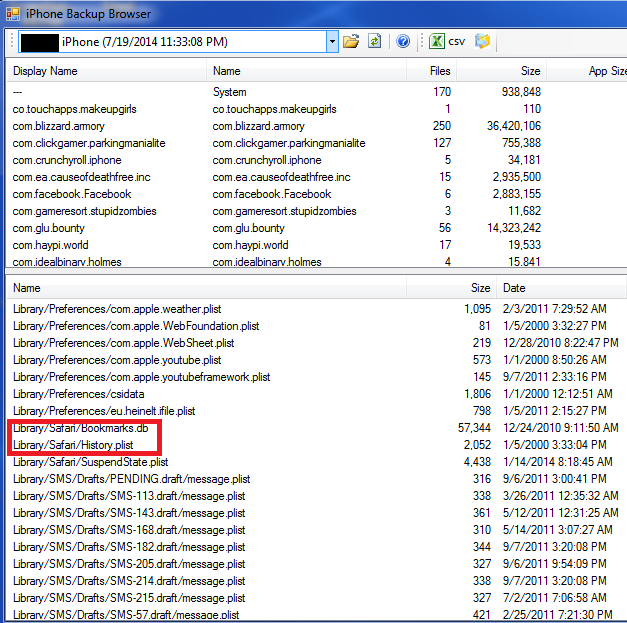
Safari is also installed on the iPhone so I figured while I was at it I might as well expand the script to handle the iPhone Internet History files. I had some test data laying around, and I was able to locate three files of interest: History.plist, Bookmarks.db and RecentSearches.plist.
While my test data came from an iPhone extraction, these types of files are also located in an iTunes backup on a computer. This means that even if you don't have access to the phone, you could get still get the Internet History. Check in the user's folder under \AppData\Roaming\Apple Computer\MobileSync\Backup, then use a tool like
iphonebackupbrowser to browse the backups and export out the files:
HistoryThe location of the History.plist file may vary depending on the model of the iPhone. Check \private\var\mobile\Library\Safari or \data\mobile\Library\Safari for this file.
Luckily, the History.plist file has the same format as the OS X version, so using the script to parse the iPhone History.plist file works the same:
safari_parser.py --history -f history.plist -o history-results.tsv
BookmarksThe location of the Bookmarks.db file may vary depending on the model of the iPhone. Check \private\var\mobile\Library\Safari or \data\mobile\Library\Safari for this file.
On an iPhone, this file is stored in an SQLite database rather then the plist format used on OS X. In the test data I had, I did not see any entries for the Reading List. To parse the iPhone Bookmarks.db file, use the following syntax:
safari_parser.py --iPhonebookmarks -f bookmarks.db -o bookmark-results.tsv
Recent SearchesI located a RecentSearches.plist file under the cache folder. The location of this file may vary depending on the model of the iPhone. Check \private\var\mobile\Library\Caches\Safari or \data\mobile\Library\Caches\Safari. This file contained a list of recent searches, about 20 or so. Use the following syntax to parse this file:
safari_parser.py --iPhonerecentsearches -f recentsearches.plist -o recentsearches-results.tsv
You can also point the script to a directory with all three files and parse them at once:
safari_parser.py -d /Users/maridegrazia/iPhoneFiles -o /Cases/InternetHistory/Reports
The Script
The Safari Parser can be download
here. It requires the biplist library which is super easy to install (directions below). However, I've also included a complied .exe file for Windows if you don't want to hassle with installing the library. A thank you to
Harlan Carvey for suggesting the
PyInstaller to compile Windows binaries for python - it worked like a charm.
To install biplist in Linux just type the following:
sudo easy_install biplist
For Windows, if you don't already have it installed, you'll need to grab the easy install utility which is included in the
setup tools from python.org. The setup tools will place easy_install.exe into your Python directory in the Scripts folder. Change into this directory and run:
easy_install.exe biplist
Remember to look at the plist files to manually to verify your results. I don't have access to every past or future version of Safari or iOS. As always, just shoot me an email or tweet if you need some modifications made.
References and Tools
Plist Editor (free plist editor for Windows)
XCode (includes free Plist Editor for OS X)
iphonebackupbrowser ( free iTunes backup browser)






















































.png)